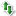When you click on links to various merchants on this site and make a purchase, this can result in this site earning a commission. Affiliate programs and affiliations include, but are not limited to, the eBay Partner Network.
I find the idea of running your own AI models locally very intriguing. I've been dipping my toes into local AI since Deepseek R1 came out. I'm using Ollama to host the models and I'm using Chatbox as the front end to communicate with Ollama. Pretty simple setup, and with a few tweaks it can be running on your local network so you can install chatbox on phone or another computer and it will talk to Ollama over your network.
Lately I've been using OLMo2 13b which is an open-source language model to help me play Skyrim. I got Skyrim on one screen and Chatbox on the other screen and OLMo2 knows a surprising amount about Skyrim lore, and gameplay mechanics. It's a lot of the same use cases for ChatGPT but this one is private and your questions aren't used to send you targeted ads, and there's not subscription fee. It's not a full replacement for ChatGPT since it's not as accurate and doesn't have access to current info but it's pretty helpful.
It's not as fast as ChatGPT but it's not really slow either at least on my current system (AMD Ryzen 7 9700x, and RTX 4070, 32GB RAM), it's fast enough
Olmo2 13b on my system generates an answer about 3x faster than I can read and that's plenty fast. As long as the AI is faster than I can read and gives a correct answer that's about all that matters. It's still cool that I can just download a big file to my PC and ask it questions and get answers with no further Internet connection required.
I made my first AI copilot in Chatbox. It is an ALT Text generator. You just paste in an image and it creates ALT Text for it
It's running the mistral-small3.1:24b multimodal model than understands image and text. It takes up all my VRAM but performance is fine
Sure, here is a refined version of the alt text for the image you provided: "A close-up image of a young girl facing the camera directly. Her eyes are highlighted with red light, suggesting that a technological or scientific device, such as facial recognition software or eye-tracking technology, is scanning or interacting with her eyes. The background is plain and light-colored, which helps to focus attention on the girl's face and the red highlights on her eyes."
Last edited by #1 STUNNA; Jun 26, 2025 at 08:26 PM.
Ok I went a little crazy and bought 96GB of CL 26 DDR5. Now I can load GPT OSS 120b into system RAM. GPTOSS 20B is actually decent, it runs on my 12GB RTX 4070 but 16GB is preferred. These local AI models can do Internet searches to find more info and give a more accurate and up to date answer.
This is my first time running flux.2 dev on my PC. Something must be wrong, but this is the result
Some recent updates that got announced by nvidia at CES, Ollama and ComfyUI now supports RTX 5000 series FP4 support which supposed to make flux.2 use a lot less RAM, that didn't seem to be the case here I was at 99% RAM and 99% VRAM, so hopefully something is wrong. but the model didn't crash at least. first time I've ever used all 96GB or RAM